昨天我們談到了一些關於虛擬記憶體的演算法,今天將繼續接下去說明
Enhanced Second-Chance Algorithm
Counting Algorithm
Page-Buffering Algorithm
Application and Page Replacement
演算法的介紹就到這裡告一段落,接下來我們來說明在分配跟存取時的相關事情吧!
Allocation of Frames
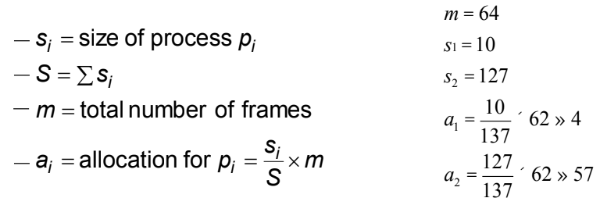
Global vs. Local Allocation
Non-Uniform Memory Access(NUMA)
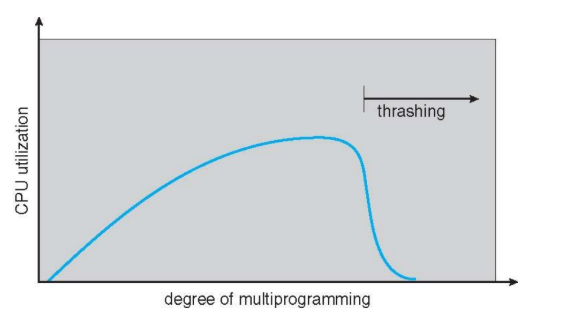
Trashing
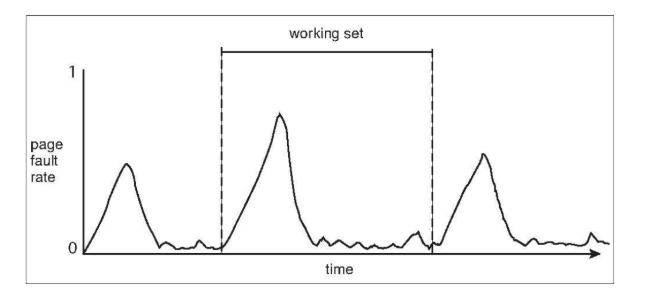
我們還剩最後一部分的虛擬記憶體說明,就留到明天繼續加油吧!

